Kaggle-Titanic 生存率预测
一、库的导入
- numpy 库 数据科学,数组分析
- pandas 库 数据类型和分析工具
- seaborn 库 + matplotlib 库 可视化数据分析
- sklearn 库 机器学习
- re 库 正则计算
相关代码:
import pandas as pd
import re
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib import style
from sklearn import linear_model
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.naive_bayes import GaussianNB二、数据获取
利用 pandas 库从 csv 文件中导入数据
相关代码:
test_df = pd.read_csv("test.csv")
train_df = pd.read_csv("train.csv")三、数据分析
1、总体分析
通过如下单行代码探寻 train.csv 文件中数据的信息
train_df.info()
train_df.describe()结果如下:

由此可见,样本容量为 891,共有 11 个 features + 1 个目标值(survived)。
进一步对数据类型为 int/float 的数据分析:
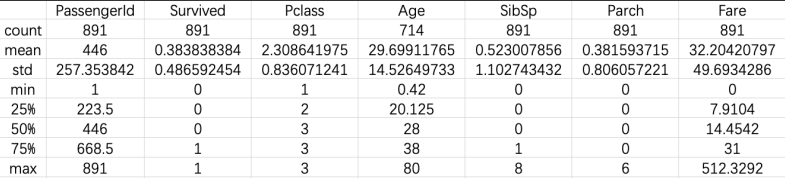
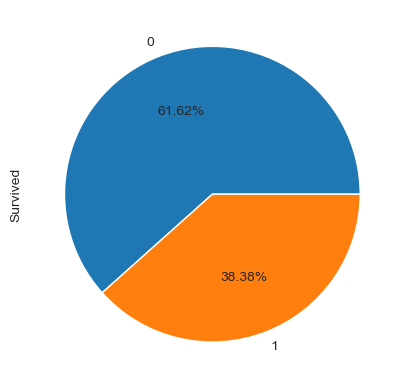
由上述结果可知,在 train.csv 中约有 38% 的乘客在事故中存活,也可以从下面的饼图中,更为直观的看出这个比例;同时,乘客的年龄从 0.4 到 80,以及在各项数据中,有若干缺失项。
2、抽取样本进行简单分析
我们选择前 10 位乘客,通过他们的信息比对以进一步确定数据分析方向:
train_df.head(10)

从 10 名乘客信息中可发现:部分数据缺失;部分值需要转换数据类型;部分数据差异化大
3、查看数据缺失率
total = train_df.isnull().sum().sort_values(ascending=False)
percent_1 = train_df.isnull().sum()/train_df.isnull().count()*100
percent_2 = (round(percent_1,1)).sort_values(ascending=False)
missing_data = pd.concat([total, percent_2],axis = 1, keys=['Total','%'])
missing_data.head(5)结果如下:

Embarked 项缺少 2 项数据,易于处理,但 Age & Cabin 个有 19.9% 和 77.1% 的缺失。
接下来寻找各关系量之间与存活率的关系。
四、Features 之间的关系
1、Age & Sex
年龄、性别与是否存活之间的关系
survived = 'survived'
not_survived = 'not survived'
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10,4))
women = train_df[train_df['Sex']=='female']
men = train_df[train_df['Sex']=='male']
ax = sns.distplot(women[women['Survived']==1].Age.dropna(),
bins=18,label = survived, ax = axes[0],kde = False)
ax = sns.distplot(women[women['Survived']==0].Age.dropna(),
bins=40,label = not_survived, ax = axes[0],kde = False)
ax.legend()
ax.set_title('Female')
ax = sns.distplot(men[men['Survived']==1].Age.dropna(),
bins=18,label = survived, ax = axes[1],kde = False)
ax = sns.distplot(men[men['Survived']==0].Age.dropna(),
bins=40,label = not_survived, ax = axes[1],kde = False)
ax.legend()
_ = ax.set_title('Male')
plt.show()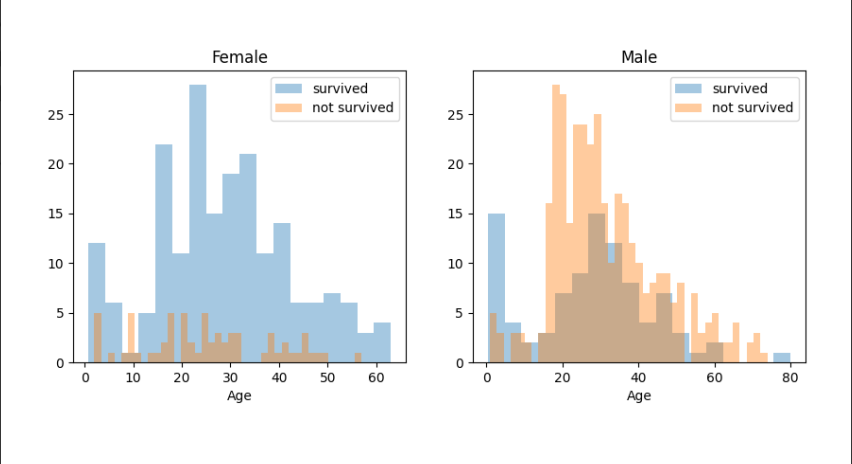
从图中看出,男性中,18~30 岁的存活率较高,女性中,14~40 岁的存活率较高;
而男性中,5~18 岁的存活率低。
我们也可以单从年龄与存活率的角度来看一下:
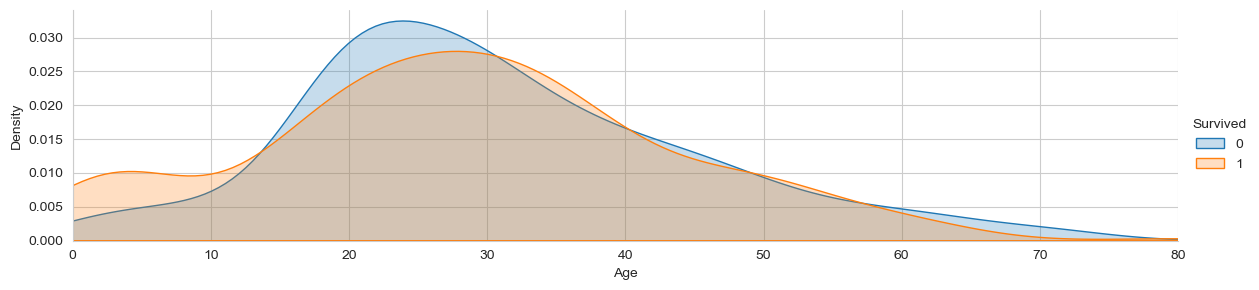
由此可见,年龄与性别对存活率有影响,之后我们要对年龄进行分组分析
2、Embarked & pclass & Sex
登船舱口,船舱等级、性别与是否存活之间的关系
FacetGrid = sns.FacetGrid(train_df, row='Embarked', size=4.5,aspect=1.6)
FacetGrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex',palette=None, order=None, hue_order=None)
FacetGrid.add_legend()
plt.show()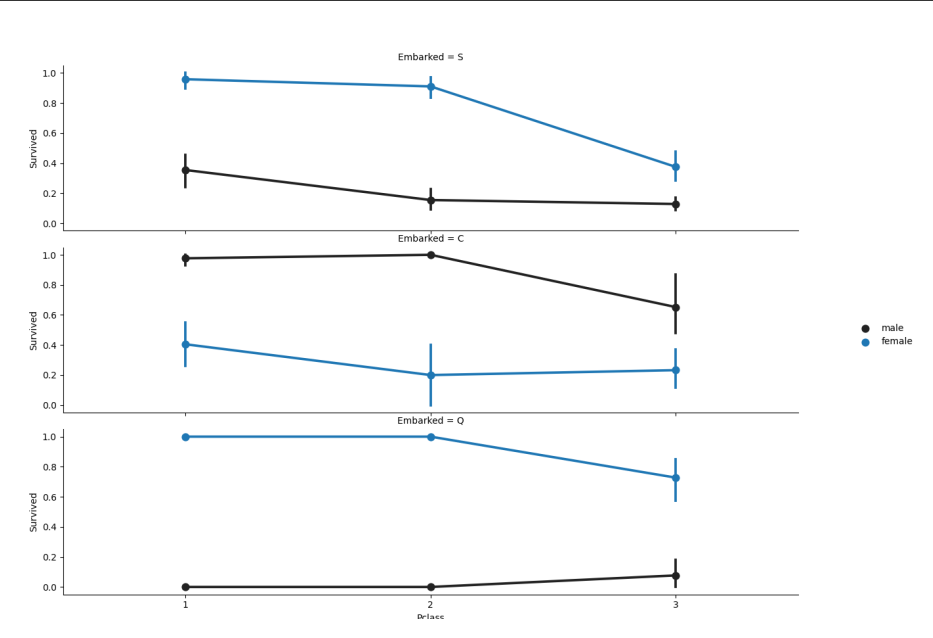
由上图可知:登船港口/性别与存活率有关,从 Q 港口和 S 港口登船的女性有更高的存活率;而在 C 港口有着相反的结果;男性则在 C 港口有较高的存活率,在 Q 和 S 港相反。
Pclass 与存活率亦有关,下面进一步探究 Pclass 与存活率的关系。
3、Pclass
船舱等级与存活率的关系
sns.barplot(x='Pclass', y='Survived', data=train_df)
plt.show()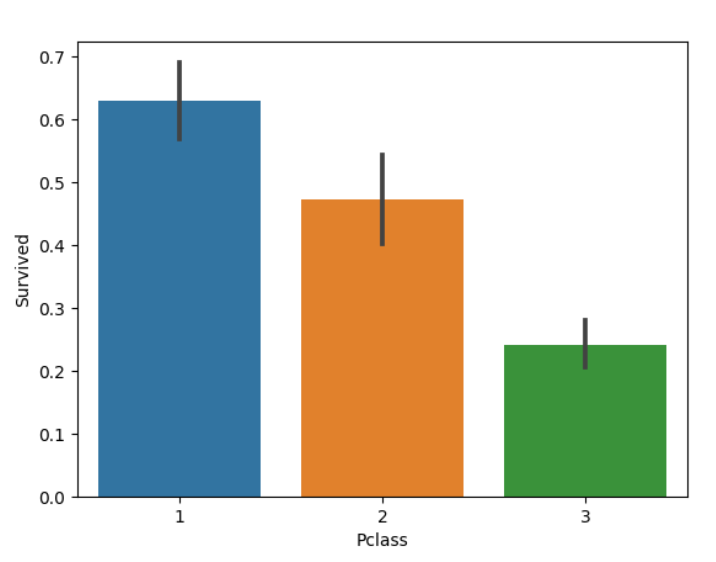
由此得知,Pclass 能决定存活率,尤其是对于 class 1 的乘客,下面进一步将图细化:
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass',size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
plt.show()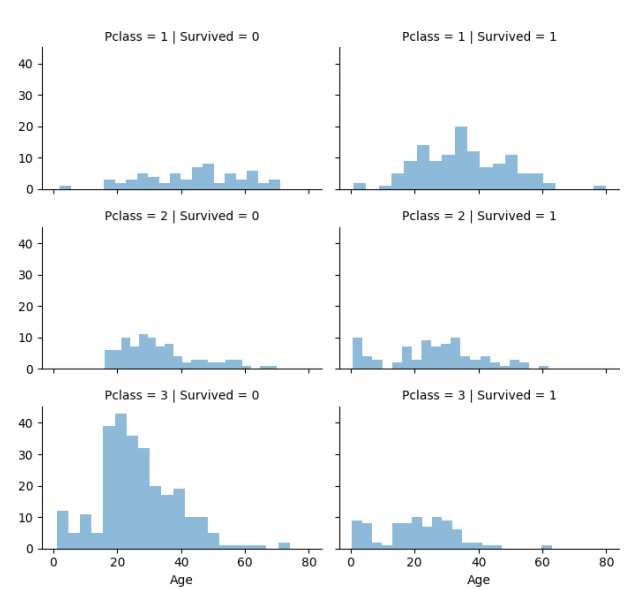
class 1 的乘客有着普遍更高的存活率,而 class 3 的乘客有着更低的存活率。
4、SibSp & Parch
配偶人数、父母子女人数与存活率的关系
将 sibsp 和 parch 看作一个整体会更有效果,通过如下代码我们可以统计乘客在船上所拥有的亲友数:
data = [train_df, test_df]
for dataset in data:
dataset['relatives'] = dataset['SibSp'] + dataset['Parch']
dataset.loc[dataset['relatives'] > 0, 'not_alone']=0
dataset.loc[dataset['relatives'] == 0, 'not_alone'] = 1
dataset['not_alone'] = dataset['not_alone'].astype(int)
print(train_df['not_alone'].value_counts())
axes = sns.factorplot('relatives','Survived',data=train_df,aspect=2.5,)
plt.show()
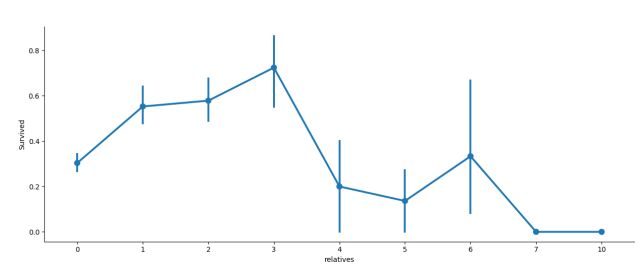
从统计结果我们可以看出,有 1~3 位亲友的乘客存活率高,有少于 1 位或多于 3 位亲友的乘客存活率较低(存在 6 位亲友的除外)
五、数据处理
首先,我们可以把 PassengerId 从 train.csv 文件中剔去,因为它并不会对乘客的存活率产生影响。
train_df = train_df.drop(['PassengerId'],axis=1)
1、缺失数据的处理
在三、3 查看数据缺失率中,共有三个缺失量,Cabin(687)、Embarked(2)、Age(177)。
处理缺失值的常用方法:
- 直接删去
- 用平均值/众数/中位数等填充
- 利用机器学习模型预测
(1) Cabin
起初决定删去‘Cabin’变量,但是像’C123‘这样的 Cabin number 与 Deck 区域有关,所以设想提取 Cabin 变量将其转化为一个数字变量并归到一个新的特征值中
deck = {"A":1, "B":2,"C":3,"D":4,"E":5,"F":6,"G":7,"U":8}
data = [train_df, test_df]
for dataset in data:
dataset['Cabin'] = dataset['Cabin'].fillna("U0")
dataset['Deck'] = dataset['Cabin'].map(lambda x: re.compile("([a-zA-Z]+)").search(x).group())
dataset['Deck'] = dataset['Deck'].map(deck)
dataset['Deck'] = dataset['Deck'].fillna(0)
dataset['Deck'] = dataset['Deck'].astype(int)
train_df = train_df.drop(['Cabin'],axis=1)
test_df = test_df.drop(['Cabin'],axis=1)(2) Age
将基于平均值/标准差的随机数代替数据中的缺失值
data = [train_df, test_df]
for dataset in data:
mean = train_df["Age"].mean()
std = test_df["Age"].std()
is_null = dataset["Age"].isnull().sum()
rand_age = np.random.randint(mean - std, mean + std, size = is_null)
age_slice = dataset["Age"].copy()
age_slice[np.isnan(age_slice)] = rand_age
dataset["Age"] = age_slice
dataset["Age"] = train_df["Age"].astype(int)(3) Embarked
首先通过 train_df['Embarked'].describe 代码确定 Embarked 中出现频率最高的字符 S = common_value
将 Embarked 中的缺失值用 common_value 代替
common_value = 'S'
data = [train_df, test_df]
for dataset in data:
dataset['Embarked'] = dataset['Embarked'].fillna(common_value)2、特征值形式的转换
首先我们通过 train_df.info 查看上述代码的操作结果
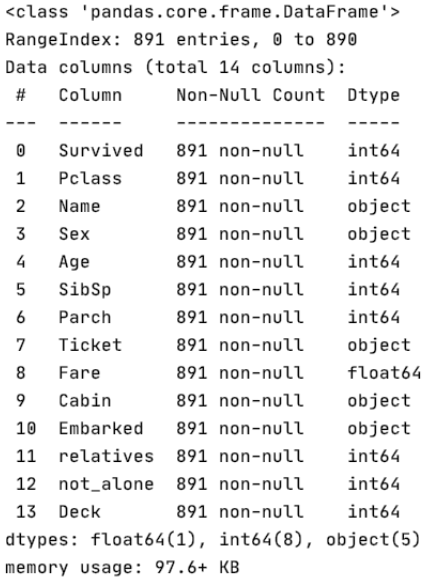
所有的缺失数据已经处理完成,接下里要处理的是四项非数字型的数据:'Name', 'Sex', 'Ticket', 'Embarked' 和一个浮点型的数据'Fare'
(1) Fare
通过 astype() 函数将数据从 float 型转为 int 型
data = [train_df, test_df]
for dataset in data:
dataset['Fare'] = dataset['Fare'].fillna(0)
dataset['Fare'] = dataset['Fare'].astype(int)(2) Name
通过新的 Title 变量代替 Name 变量
data = [train_df, test_df]
titles = {"Mr":1,"Miss":2,"Mrs":3,"Master":4, "Rare":5}
for dataset in data:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.',expand=False)
dataset['Title'] = dataset['Title'].replace(['Lady','Countess', 'Capt', 'Col', 'Don', 'Dr', \
'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle','Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
dataset['Title'] = dataset['Title'].map(titles)
dataset['Title'] = dataset['Title'].fillna(0)
train_df = train_df.drop(['Name'],axis=1)
test_df = test_df.drop(['Name'],axis=1)(4) Sex
用 0 和 1 表示性别
genders = {"male": 0, "female": 1}
data = [train_df, test_df]
for dataset in data:
dataset['Sex'] = dataset['Sex'].map(genders)(5) Ticket
通过 train_df['Ticket'].describe() 查看 Ticket 栏的整体信息,发现互异值过多,难以转化,故弃之
train_df = train_df.drop(['Ticket'], axis=1)
test_df = test_df.drop(['Ticket'],axis=1)(6) Embarked
ports = {"S":0,"C":1,"Q":2}
data = [train_df, test_df]
for dataset in data:
dataset['Embarked'] = dataset['Embarked'].map(ports)3、数据分类/组
(1) Age
我们首先要将不同的年龄段分成不同的组,并归为一个 AgeGroup 变量
data = [train_df, test_df]
for dataset in data:
dataset['Age'] = dataset['Age'].astype(int)
dataset.loc[ dataset['Age'] <= 11, 'Age'] = 0
dataset.loc[(dataset['Age'] > 11) & (dataset['Age'] <= 18),
'Age'] = 1
dataset.loc[(dataset['Age'] > 18) & (dataset['Age'] <= 22),
'Age'] = 2
dataset.loc[(dataset['Age'] > 22) & (dataset['Age'] <= 27),
'Age'] = 3
dataset.loc[(dataset['Age'] > 27) & (dataset['Age'] <= 33),
'Age'] = 4
dataset.loc[(dataset['Age'] > 33) & (dataset['Age'] <= 40),
'Age'] = 5
dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 66),
'Age'] = 6
dataset.loc[ dataset['Age'] > 66, 'Age'] = 6(2) Fare
通过 qcut() 函数确定划分范围,然后对数据进行分组
data = [train_df, test_df]
for dataset in data:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[(dataset['Fare'] > 31) & (dataset['Fare'] <= 99), 'Fare'] = 3
dataset.loc[(dataset['Fare'] > 99) & (dataset['Fare'] <= 250), 'Fare'] = 4
dataset.loc[ dataset['Fare'] > 250, 'Fare'] = 5
dataset['Fare'] = dataset['Fare'].astype(int)六、建立机器学习模型
现在我们要训练不同的几种机器学习模型并比较他们的结果,因为这些数据集并没有为他们的测试集提供标签,所以我们需要用对测试集的预测来对每个算法进行比较
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy()1、八种机器学习模型
(1) Stochastic Gradient Descent(SGD)
# 随机梯度下降
sgd = linear_model.SGDClassifier(max_iter=5, tol=None)
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
sgd.score(X_train, Y_train)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)(2) Random Forest
# 随机森林
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_prediction = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)(3) Logistic Regression
# 逻辑回归分析
logreg = LogisticRegression(max_iter=1000)
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_train)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)(4) K Nearest Neighbor
# k-近邻算法
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)(5) Gaussian Naive Bayes
# 朴素贝叶斯分类器
Y_pred = gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)(6) Perceptron
# 感知机
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)(7) Linear Support Vector Machine
# 支持向量机
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)(8) Decision Tree
# 决策树
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)2、探究最佳模型
results = pd.DataFrame({
'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression',
'Random Forest', 'Naive Bayes', 'Perceptron',
'Stochastic Gradient Decent', 'Decison Tree'],
'Score': [acc_linear_svc, acc_knn, acc_log, acc_random_forest,
acc_gaussian, acc_perceptron, acc_sgd, acc_decision_tree]
})
result_df = results.sort_values(by='Score', ascending=False)
result_df = result_df.set_index('Score')
print(result_df.head(9))通过上述代码对各机器学习模型进行对比,我们得出的结果如下图所示:

从结果中我们不难看出,随机森林的效果最好
3、k 折交叉验证
下面对随机森林进行 10 折交叉验证,我们会得到 10 个不同的分数
from sklearn.model_selection import cross_val_score
rf = RandomForestClassifier(n_estimators=100)
scores = cross_val_score(rf, X_train, Y_train, cv=10, scoring="accuracy")
print("scores:", scores)
print("Mean:", scores.mean())
print("Standard Deviation:", scores.std())
我们的模型有大约 82% 上下 4% 的置信度,仍可以进一步提升模型的置信度
4、优化
(1) Features 的权重
我们首先通过随机森林的特性查看各特征值的权重
importance = pd.DataFrame({
'feature': X_train.columns, 'importance': np.round(random_forest.feature_importances_, 3)
})
importance = importance.sort_values('importance', ascending=False).set_index('feature')
print(importance.head(15))
importance.plot.bar()

由此可见,not_alone 和 Parch 在该模型中并不重要,所以我们将这两项从数据集中剔去
train_df = train_df.drop("not_alone", axis=1)
test_df = test_df.drop("not_alone", axis=1)
train_df = train_df.drop("Parch", axis=1)
test_df = test_df.drop("Parch", axis=1)(2) 再次进行随机森林的模型训练
random_forest = RandomForestClassifier(n_estimators=100, oob_score=True)
random_forest.fit(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
print(round(acc_random_forest, 2), "%")
print("-" * 100)
print("oob score:", round(random_forest.oob_score_, 4) * 100, "%")运行结果为 92.7%,结果较好
注:OOB_SCORE 是一种非常强大的模型验证技术,专门用于随机森林算法以实现最小方差结果
(4) 超参数调整
param_grid = {
"criterion" : ["gini", "entropy"],
"min_samples_leaf": [1, 5, 10, 25, 50, 70],
"min_samples_split" : [2, 4, 10, 12, 16, 18, 25, 35],
"n_estimators": [100, 400, 700, 1000, 1500]
}
from sklearn.model_selection import GridSearchCV, cross_val_score
rf = RandomForestClassifier(n_estimators=100, max_features='auto',
oob_score=True, random_state=1, n_jobs=-1)
clf = GridSearchCV(estimator=rf, param_grid=param_grid, n_jobs=-1)
clf.fit(X_train, Y_train)
clf.best_params_调整结果如下:{'criterion': 'gini', 'min_samples_leaf': 5, 'min_samples_split': 2, 'n_estimators': 400}
(5) 测试新的参数
random_forest = RandomForestClassifier(criterion="gini",
min_samples_leaf=5,
min_samples_split=2,
n_estimators=400,
max_features='auto',
oob_score=True,
random_state=1,
n_jobs=-1
)
random_forest.fit(X_train, Y_train)
Y_prediction = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
print("oob score:", round(random_forest.oob_score_, 4) * 100, "%")测试结果为 83.05%
(6) 混淆矩阵
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
predictions = cross_val_predict(random_forest, X_train, Y_train, cv=3)
confusion_matrix(Y_train, predictions)混淆矩阵的结果如下:

5、验证
(1)计算准确率和召回率
准确率:全体样本中,预测正确的比例(正确率高)
召回率:正样本中被预测成功的比例(覆盖面广)
from sklearn.metrics import precision_score, recall_score
print("Precision:", precision_score(Y_train, predictions))
print("Recall:", recall_score(Y_train, predictions))
print("-" * 100)计算结果如下:

(2) 计算 Fscore
from sklearn.metrics import f1_score
print(f1_score(Y_train, predictions))
print("-" * 100)计算结果为:0.7716049382716048
(3) 绘制 PR 曲线
from sklearn.metrics import precision_recall_curve
# getting the probabilities of our predictions
y_scores = random_forest.predict_proba(X_train)
y_scores = y_scores[:, 1]
precision, recall, threshold = precision_recall_curve(Y_train, y_scores)
def plot_precision_and_recall(precision, recall, threshold):
plt.plot(threshold, precision[:-1], "r-", label="precision", linewidth=5)
plt.plot(threshold, recall[:-1], "b", label="recall", linewidth=5)
plt.xlabel("threshold", fontsize=19)
plt.legend(loc="upper right", fontsize=19)
plt.ylim([0, 1])
plt.figure(figsize=(14, 7))
plot_precision_and_recall(precision, recall, threshold)
plt.show()绘制的曲线如下:

(4)ROC 和 AUC 曲线的绘制
from sklearn.metrics import roc_curve
false_postive_rate, true_postive_rate, threshold = roc_curve(Y_train, y_scores)
def plot_roc_curve(false_postive_rate, true_positive_rate, label=None):
plt.plot(false_postive_rate, true_positive_rate, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'r', linewidth=4)
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate (FPR)', fontsize=16)
plt.ylabel('True Positive Rate (TPR)', fontsize=16)
plt.figure(figsize=(14, 7))
plot_roc_curve(false_postive_rate, true_postive_rate)
plt.show()绘制的曲线如下图:
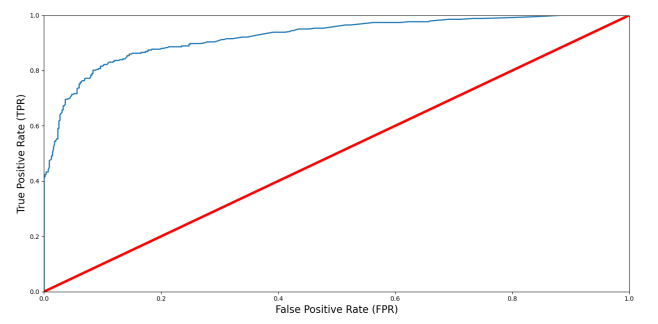
(5)ROC 和 AUC 值的计算
from sklearn.metrics import roc_auc_score
r_a_score = roc_auc_score(Y_train, y_scores)
print("ROC-AUC-Score:", r_a_score)
print("-" * 100)计算结果如下:
ROC-AUC-Score: 0.9228048871419592
此时我们认为该模型的准确率已经足够,模型训练结束。
七、总结
我们从对数据的分析处理出发,对缺失的数据值进行处理,然后将部分特征值进行数据格式的转化及分类。在此之后,我们建立了 8 种模型用以测试,并从中选取最合适的一种【随机森林】对其进行交叉验证以及超参数调整等模型优化。最后我们计算了该模型的混淆矩阵、准确率与召回率以及 F-score 对最终的模型进行验证,最终得出我们的模型能满足需求,本次项目结束。